Background
Prefix matching is a critical operation in various applications, particularly in string searching and data retrieval systems. It allows for efficient querying of strings that start with a given substring, making it essential for functionalities like autocomplete, search suggestions, and routing in network systems.
Solution 1: The TRIE data structure
A Trie, or prefix tree, is a specialized tree structure that facilitates prefix matching by storing characters of strings in a hierarchical manner. Each node represents a character, and paths from the root to the nodes represent prefixes of the strings stored in the Trie. The complexity of tries grows with the length of the key, not the number of elements in the structure. They suffer bad space performance when the keys are sparse.
Understanding downside of using Trie

Each node in a trie represents a portion of a key, specifically the beginning part shared by multiple keys. This shared beginning is called a prefix. We don’t need to explicitly store this prefix in the node because we can deduce it from the path we took to reach that node. The crucial information each node needs is how to locate its child nodes.
To locate child nodes, we need a mechanism to identify all nodes that represent prefixes one character longer than the current one. This is the purpose of the children array. In this implementation, we're working with an 8-bit character set, which means there are 256 possible characters for each position in the key. This results in what's called a fan-out of 256, meaning each node can potentially have up to 256 child nodes.
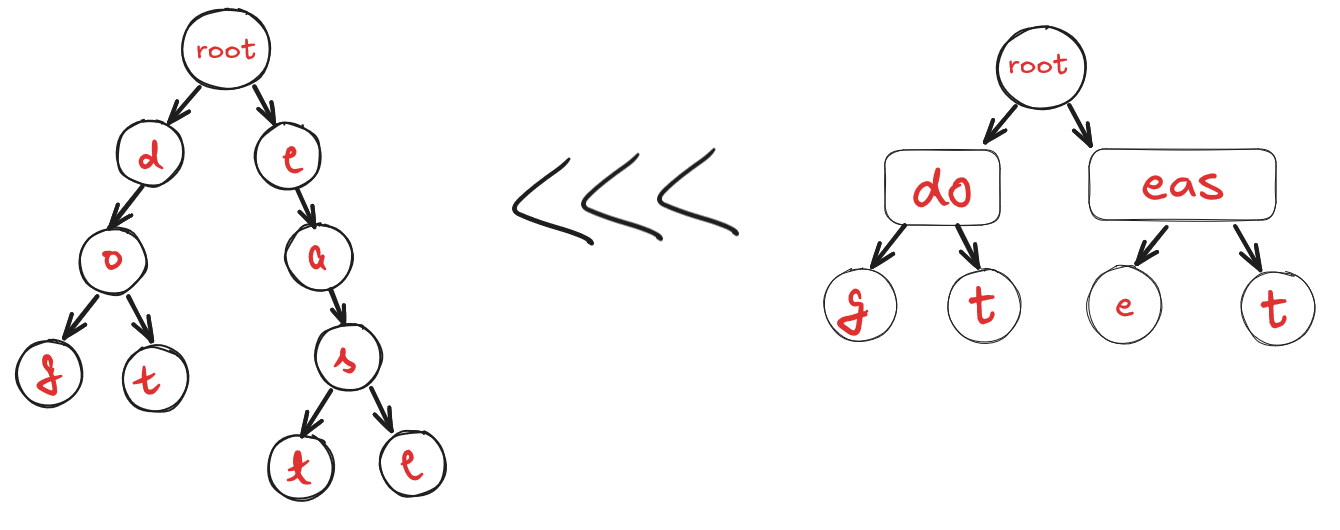
The inefficiency of this trie structure becomes apparent when we consider the potential for wasted space in each node. Let’s illustrate this with our example words: “dog”, “dot”, “ease”, and “east”.
The root node would have two valid pointers: one to “d” and one to “e”.
- The “d” node would have one pointer to “o”.
- The “o” node would have pointers to “g” and “t”.
- The “e” node would have one pointer to “a”.
- The “a” node would have one pointer to “s”.
- The “s” node would have pointers to “e” and “t”.
In total, we have 9 nodes. Assuming we’re using the English alphabet (26 letters), each node would have an array of 26 pointers. This means we have 9 * 26 = 234 pointers in total. However, only 7 of these pointers are actually used (the ones we described above). This means 227 out of 234 pointers, are empty and wasting space.
If each pointer occupies 8 bytes of memory, we’re using 234 * 8 = 1,872 bytes to store what is essentially just 15 bytes of information (the letters in our four words). This demonstrates the significant memory inefficiency of this trie implementation, especially for small datasets.
Solution 2: Radix Tree data structure
I came across this data structure while going through the internals of fastify.js and go-fiber.
A Radix Tree, or compact prefix tree, is an optimization of the Trie that combines nodes with single children to reduce space complexity. It retains the same hierarchical structure but eliminates unnecessary nodes, making it more memory-efficient.
If we take the example strings provided above we can see that the corresponding Radix Tree would look like:

When we compress our standard trie down into a radix tree such that every single child node was merged with its parent, we only needed 6 nodes to represent that same group of keys. Recall that every time we intialize a node, we also need to initialize an array with (usually) 26 keys, one for each of the 26 letters of the English alphabet. By eliminating 3 nodes in the process of compression, we saved that much space and memory that we would have needed to allocate otherwise.
Performance:
- Space Efficiency: By merging nodes with single children, Radix Trees can significantly reduce memory usage compared to standard Tries.
- Search Complexity: The search operation remains O(m) on average, similar to Tries, but with reduced overhead due to fewer nodes.
Real-life use cases:
- API Request Routing: Fastify, a high-performance web framework for Node.js, employs a Radix Tree for its routing mechanism, optimizing the way it handles incoming requests and matches them to defined routes. This approach enhances performance and memory efficiency, especially in applications with numerous routes.
Let’s say we have the following routes:
fastify.get('/api/users', handleGetUsers)
fastify.get('/api/users/:id', handleGetUser)
fastify.get('/api/products', handleGetProducts)
fastify.get('/api/products/:id', handleGetProduct)
fastify.get('/blog/posts', handleGetBlogPosts)
fastify.get('/blog/posts/:id', handleGetBlogPost)The Radix Tree for all these routes would look like:
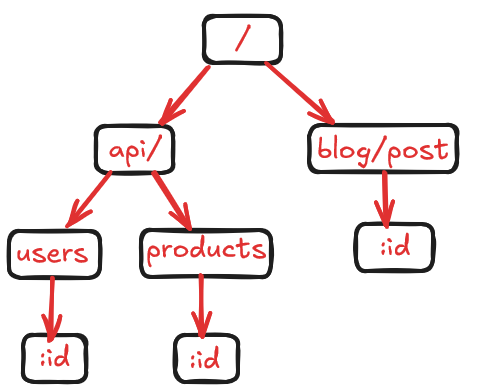
Key points about this compressed structure:
- The “/api/” prefix is stored once, saving memory and reducing lookup time.
- The “blog/posts” path is compressed into a single node.
- Parameter nodes (“:id”) are still separate to allow for dynamic routing.
When Fastify receives a request, it traverses this tree to find the matching route. For example, a request to “/api/users/123” would:
- Match the “/api/” node
- Then match the “users” node
- Finally match the “:id” parameter node, extracting “123” as the id
This structure allows Fastify to perform route matching very quickly, even with a large number of routes, making it highly performant for web applications.
2. IP Address Lookup in DNS: Suppose we want to store and look up the following IP addresses:
192.168.0.1192.168.0.2192.168.0.10192.168.1.1
Step 1: Binary Representation
Here are the binary representations of the IP addresses:
192.168.0.1→11000000.10101000.00000000.00000001192.168.0.2→11000000.10101000.00000000.00000010192.168.0.10→11000000.10101000.00000000.00001010192.168.1.1→11000000.10101000.00000001.00000001
Step 2: Building the Radix Tree
- Insert
192.168.0.1:
- Start with an empty radix tree.
- Insert the full binary string:
11000000.10101000.00000000.00000001.
2. Insert 192.168.0.2:
- The first 30 bits (
11000000.10101000.00000000.000000) are the same as192.168.0.1. - Since the prefixes match, the tree will branch only at the point of difference (last bit):
01for.1and10for.2.
3. Insert 192.168.0.10:
- The first 28 bits (
11000000.10101000.00000000.0000) match the existing entries. - At the 29th bit, the path will branch:
0001for.1,0010for.2, and1010for.10.
4. Insert 192.168.1.1:
- The first 25 bits match (
11000000.10101000.00000001). - The tree will branch off at the 26th bit for this address.
Step 3: Path Compression
In a standard trie, we would store each bit of the binary address in separate nodes, leading to a tree that is 32 levels deep for each address. However, with path compression, we compress nodes that have only one child by collapsing them into a single edge, representing the common prefix.
Path Compression Example:
Let’s focus on 192.168.0.1 and 192.168.0.2:
- The first 30 bits of these two addresses are identical:
11000000.10101000.00000000.000000. - Instead of creating 30 separate nodes, we compress them into a single edge that represents the entire 30-bit prefix.
- At the point where the paths diverge (31st bit), we create a branch:
01for.1and10for.2.
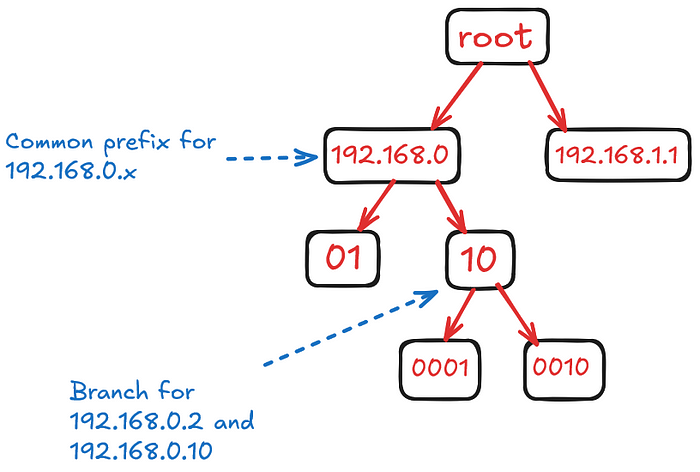
Final Compressed Radix Tree Structure:
- Root: Represents the common prefix of all IP addresses (
192.168.0in decimal, or the first 24 bits in binary:11000000.10101000.00000000). - Branch 1: Represents
192.168.0.1and192.168.0.2, with the compressed path up to the 30th bit, then branching into two nodes (01for.1and10for.2). - Branch 2: Represents
192.168.0.10with a longer path compressed up to 28 bits, and the unique part represented thereafter. - Branch 3: Represents
192.168.1.1starting to diverge at the 25th bit with a different compressed path.
Visualization of Path Compression
Conclusion
In summary, both Tries and Radix Trees serve crucial roles in prefix matching scenarios. While Tries are straightforward and effective for many applications, Radix Trees offer enhanced space efficiency without sacrificing performance. The choice between them depends on specific use cases and constraints related to memory usage and speed requirements.
References & Further Read
- OpenGenus – https://iq.opengenus.org/radix-tree/amp/
- Advance Routing Tech – https://astconsulting.in/blog/2023/07/22/advanced-routing-fastify/
- Adaptive Radix Tree – https://db.in.tum.de/~leis/papers/ART.pdf
Hope you learnt something new today!
AnkitCode99 here….